Eu não sou uma pessoa muito carnavalesca, mas um dos assuntos da semana na internet foi a nova vinheta da Rede Globo para o Carnaval. Tradicionalmente, essa vinheta apresenta uma mulher negra nua (ou semi nua) sambando, chamada popularmente de "globeleza", às vezes acompanhada, às vezes sozinha. Entretanto, este ano, a vinheta apareceu diferente. Não apenas a globeleza aparece vestida, como ainda em seu figurino apresenta representação do Carnaval das várias regiões do Brasil (
veja o vídeo). A vinheta gerou polêmica na mídia social. Capturei uma parte das várias mensagens sobre o assunto através da palavra-chave "globeleza". Foram cerca de 25 mil tweets e 20 mil contas que atuaram na rede. Meu objetivo aqui era analisar, através de um combo de análise de contingência e análise de redes, quais argumentos foram mais centrais na discussão.
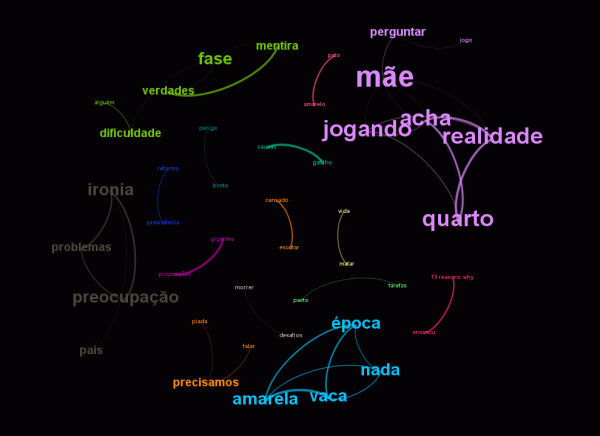
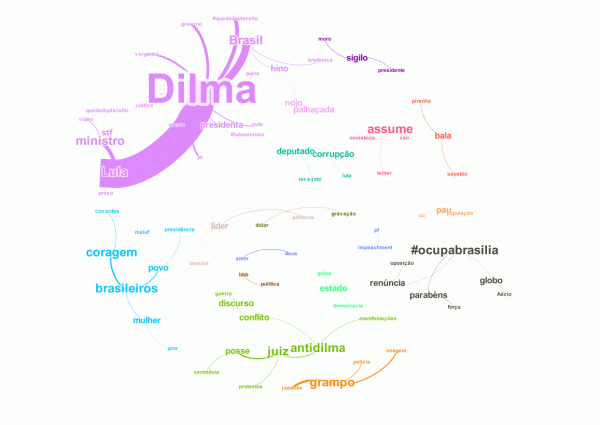
Vou discutir neste post apenas os grafos. Os dados brutos vão ficar para um possível artigo. No grafo a seguir (clique para ver em tamanho maior), vemos os principais conceitos associados (co-ocorrência) na discussão (tomando como unidade o tweet). As cores indicam tendência a co-ocorrer (ou seja, dos conceitos a pertencerem a um mesmo grupo) e o tamanho dos conceitos indica sua frequencia de associação no conjunto de dados.
Há quatro conceitos centrais: "globeleza", "roupa", "nudez" e "globo". Esses quatro conceitos representam o cerne da discussão, ou seja, a maior parte da conversação girou em torno do fato da globeleza estar vestida. As co-ocorrências mais comuns neste cluster rosa aparecem acima, a direita. Ali vemos os conceitos "mulher", "Brasil", "vinheta"e "cultura". Em meio a este cluster, vemos também o conceito "corpo"e "exposição". O debate, assim, esteve centrado também na questão do corpo da mulher, associado à uma questão cultural no Brasil. À esquerda, outro conceito importante é "carnaval". Nesse grupo rosa, vemos também principalmente conceitos associados à "gostei", "amei" e "adorei". É interessante notar, entretanto, que embora a maioria dos conceitos associados seja positivo, há também conceitos negativos associados a "politicamente" e "correto", "conservadorismo", "direita" e etc. Também é interessante observar que o termo "mulata" é o único associado neste grupo. Poderíamos dizer que este cluster sumariza os argumentos favoráveis à mudança da maioria dos tweets (gostaram da mudança da mulher de roupa, sem "exposição" do "corpo"; ou reclamaram da vinheta como um exemplo de "conservadorismo" argumentando que a mulher sem roupa é "cultura" do "carnaval"). No grupo azul, temos a questão ativista. Ali, por exemplo, vemos a palavra "negra" como central, ou seja, associando a vinheta à "objetificação", "sexualização" da mulher negra (inclusive com um "temer" ali no meio que não vi como entrou na discussão). O grupo verde, do outro lado, associou a nova vinheta à representação e ao folclore do Brasil. Esses dois grupos representam posicionamentos positivos em torno da vinheta. Os posicionamentos negativos são representados pelo grupo laranja (associando a nova vinheta ao "bela", "recatada" como um discurso conservador, exigindo outros tipos de mulheres na vinheta) e o grupo vermelho ("símbolo" e "chatice", associando a nova vinheta também ao conservadorismo).

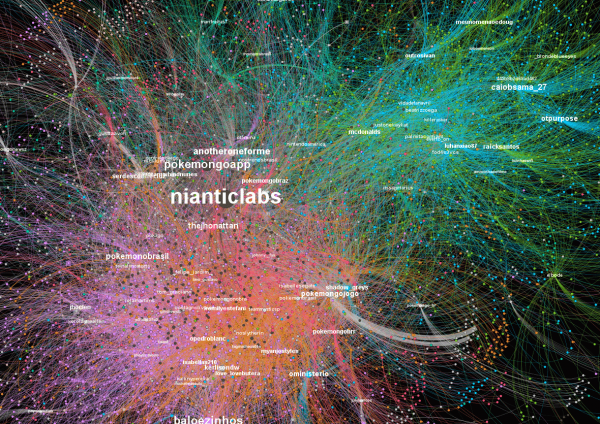
No grafo anterior (clique na imagem para ver em tamanho maior), observamos os dados normalizados, para apresentar de modo mais claro as diversas associações que mais circularam. Há argumentos negativos grupos amarelo, rosa claro, laranja, verde musgo e rosa) e positivos (azul, verde escuro, verde bandeira, vermelho, azul claro, azul escuro e rosa escuro). De modo geral, entretanto, como vimos no primeiro grafo, embora tenhamos uma pluralidade de argumentos (indicando a polêmica e o debate), há uma predominância de um discurso positivo com relação à vinheta em si. É interessante acompanhar esta polêmica para ver se esta predominância se mantém, mas achei bastante interessante a presença do discurso ativista contra a objetificação da mulher negra que, no grafo geral, praticamente desaparece, em detrimento de elogios associados à presença da roupa (portanto, mais conservadores).